
Несмотря на разнообразие применяемых методик микроскопии, достоверность полученных измерительных результатов, в частности при разбраковке изделий, остается достаточно низкой. Это объясняется в ряде случаев такими причинами как шум видеосигнала, остаточная нелинейность развертки, проявляющаяся в ходе собственно измерений (а не только при калибровке увеличения), свободные параметры, т.н. «скрытые» свободные параметры и т.д. и т.п. В общем случае основная проблема заключается в разнотипности получаемых данных и, как следствие, в сложности их сопоставления для всестороннего анализа с целью получения изображений, объединяющих информацию как о форме и расположении объектов на поверхности и в объеме материала, так и об их качественном составе. При этом наилучший результат достигается с помощью фильтрации входных сигналов разнотипных данных и их последующего совмещения как единого 3D-изображения.
Проблемы и методы измерений размеров в технологии микроэлектроники, методы фильтрации сигналов, сегментации изображений достаточно глубоко исследованы и широко представлены в современной научной литературе. Всесторонней проработкой этой тематики занимались как отечественные, так и зарубежные специалисты в области обработки сигналов и изображений: В.А. Абрамов, Ю.С. Андреев, Ю.М. Баяковский, А.А. Богуславский, В.П. Вежневец, Ю.И. Журавлев, М.Д. Казанов, В.Ф. Нестерук, В.Д. Колдаев, В.В. Сергеев, В.А. Сойфер, С.В. Яблонский, Л.П. Ярославский, Russel B, Zhang Y.J., R. Woods, P. Wiola, M. Johns, L. Davis, R. Gonzalez, W. Lyppel, Huang T.S., D. Prevytt, A. Rozenfeld, T. Павлидис, W. Pratt и др. Однако, единого подхода к обработке разнотипных сигналов и их последующему совмещению, т.е. к осуществлению 3D- рэндеринга до сих пор не существует.
Таким образом, при современном уровне автоматизации межоперационного контроля качества изделий микроэлектроники (МЭ) проблема разработки соответствующих алгоритмов и методики для осуществления 3D-рэндеринга с целью повышения достоверности результатов измерений в процессе разбраковки продукции является весьма актуальной.
В настоящее время основным сдерживающим фактором развития данного направления является низкая производительность непредвзятого 3D-рендеринга на неспециализированных устройствах типа персональных компьютеров, управляющих исследованиями образцов с применением стандартных методик. В [1], [2] и [4] были рассмотрены предпосылки для выбора алгоритма и пути его модификации приведшие к разработке “эффективного алгоритма трассировки лучей на основе метода Монте-Карло для получения 3D-сцены”. Как было показано в [1], для достижения наибольшей эффективности при реализации данного алгоритма предпочтительно использование архитектуры параллельных вычислений CUDA, позволяющей единовременно трассировать несколько лучей.
Основным сдерживающим фактором, мешающим реализации разработанных и представленных в [1] и [2] параллельных алгоритмов является невозможность глобальной синхронизации между всеми потоками на GPU. Данное ограничение является аппаратным. GPU построены таким образом, что состоят из нескольких потоковых мультипроцессоров. Для запуска GPU кода программисту необходимо структурировать все потоки в специальные группы, называемые “блоками”. Один блок потоков гарантированно должен выполняться на одном мультипроцессоре. Но мультипроцессоры имеют возможность исполнять сразу несколько блоков (если общее количество потребляемых им ресурсов не превышает доступного в мультипроцессоре) и помещать оставшиеся в “очереди”. Главная проблема такого подхода заключается в том, что блоки, попавшие в очередь, не могут начать выполнение, пока запущенные на мультипроцессоре – не завершатся. Это является следствием отсутствия поддержки сохранения и восстановления контекста запущенных блоков на аппаратном уровне, поскольку это потребовало бы сохранения всей локальной памяти мультипроцессора вне самого мультипроцессора. Единственной возможностью выступает глобальная память GPU, но следует учитывать, что она является самой медленной в устройстве и операции по сохранению/восстановлению контекста были бы слишком затратными, и вообще говоря – бесполезными (за это время выгоднее дать текущим блокам завершить свое выполнение, нежели постоянно ждать пока они загрузятся/выгрузятся из глобальной памяти).
Поэтому, если GPU код имеет какую-либо попытку реализации глобальной синхронизации между всеми потоками (например, при помощи специального мьютекса в глобальной памяти, доступной из всех потоков) – нет никаких гарантий, что выполнение такого кода не вызовет взаимной блокировки между блоками. Более того, взаимная блокировка – это единственный возможный исход запуска такого кода (за исключением ситуации, когда количество блоков и их ресурсопотребление таково, что все блоки одновременно “помещаются” на всех мультипроцессорах, не попадая в очередь). Фактически возникает ситуация, когда блоки потоков, достигшие барьера глобальной синхронизации, ждут блоков, заблокированных в очереди и не способных начать выполнение каких-либо инструкций.
По этой причине, в разработанный алгоритм потребовалось внести некоторые изменения. Основная идея этой версии алгоритма (рис. 1) лежит в использовании лишь одного блока потоков в алгоритме разбиения узлов дерева (т.е. построении ускоряющей структуры). Другими словами, после этапа траверса (когда необходимые к разбиению AABB[1] уже помечены) первый блок, попытавшийся начать разбиение конкретного AABB – производит его, в то время как другие – пытаются произвести аналогичную операцию над остальными.
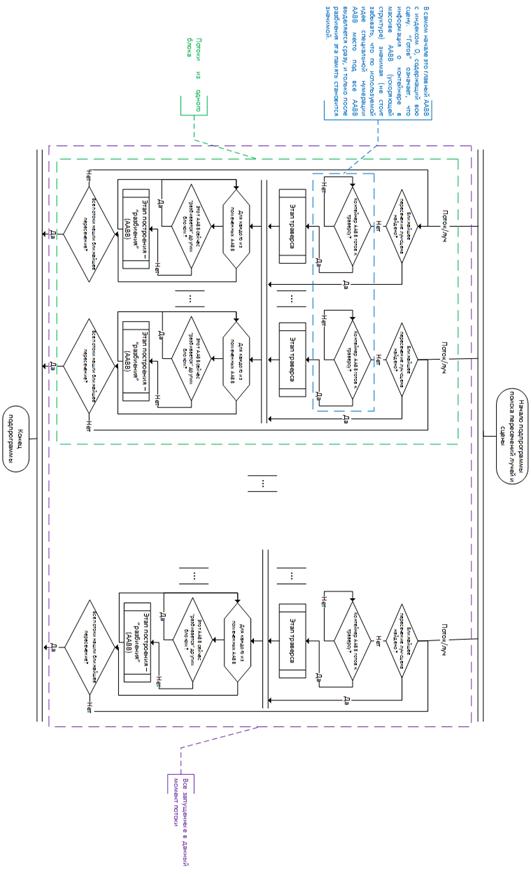
Рисунок 1. Основной цикл параллельно алгоритма адаптивного построения и траверса ускоряющей структуры (с учетом архитектурных особенностей GPU
Таким образом, только один блок потоков разбивает AABB в отдельный момент времени. Несколько блоков могут одновременно обрабатывать несколько узлов, поскольку процесс разбиения отдельного узла равносилен сортировке отдельной части массива, не пересекающейся с другими (в случае разбиения узлов одного уровня или разных поддеревьев). Кроме того, проверка того, что AABB уже начал разбивать другой блок потоков, производится при помощи специального флага, хранящегося вместе с узлом дерева (все операции с этим флагом являются атомарными, также предоставляемыми интерфейсом CUDA).
В результате такого представления получен алгоритм, эффективный для применении в ГП с поддержкой технологии CUDA, что позволяет интегрировать разрабатываемое решение в любой ПК, являющийся управляющим либо самой АСК, либо ее элементами, отвечающими за разбраковку продукции без их серьезной модификации.
СПИСОК ЛИТЕРАТУРЫ :
- Федоров П.А. «Повышение достоверности измерений при разбраковке изделий микроэлектроники на основе эффективного алгоритма трассировки лучей для получения 3d-сцены.» “Естественные и технические науки”, №9 2015 cтр. 123.
- Федоров П.А., Федоров А.Р. «Предпосылки для разработки параллельного алгоритма и методики осуществления 3d рендеринга в автоматизированных Системах контроля изделий микроэлектроники», II Международная научно-практическая конференция «Информационные технологии естественных и математических наук» (г. Ростов-на-Дону)». / Сборник научных трудов по итогам международной научно-практической конференции (10 августа 2015г), стр. 14.
- Аунг Ч.Х., Тант З.П., Федоров А.Р., Федоров П.А. Разработка алгоритмов обработки изображений интеллектуальными мобильными роботами на основе нечеткой логики и нейронных сетей // Современные проблемы науки и образования. – 2014. – № 6; URL: science-education.ru/120-15579.(ВАК)
- Федоров А.Р., Федоров П.А. Разработка алгоритмов непредвзятого 3d рендеринга // Современные проблемы науки и образования. – 2014. – № 6; URL: science-education.ru/120-15578.(ВАК)
[1] В качестве узлов дерева ускоряющей структуры используется Axis Aligned Bounding Box (AABB). AABB представляет собой параллелепипед со сторонами, параллельными плоскостям, образованным осями координат. Ясно, что такой фигурой достаточно легко ограничить объекты, или отдельные полигоны сцены. Тогда построение ускоряющей структуры представимо как процесс итеративного разбиения узлов дерева AABB (главным узлом дерева является исходный AABB, содержащий всю сцену).[schema type=»book» name=»ОСОБЕННОСТИ РАЗРАБОТКИ АЛГОРИТМОВ 3D-РЕНДЕРИНГА ДЛЯ ГРАФИЧЕСКИХ ПРОЦЕССОРОВ, ИСПОЛЬЗУЮЩИХ ТЕХНОЛОГИЮ CUDA » description=»В статье рассматриваются пути повышения достоверности измерений при разбраковке изделий микроэлектроники в автоматизированных системах контроля (АСК). В качестве такого пути предлагается 3D-рендеринг изображения изучаемого объекта. Обсуждается использование эффективного алгоритма трассировки лучей на основе метода Монте-Карло для получения 3D-сцены, обсуждаются особенности применения графических процессоров, использующих технологию CUDA.» author=»Федоров Петр Алексеевич» publisher=»Басаранович Екатерина» pubdate=»2017-01-25″ edition=»ЕВРАЗИЙСКИЙ СОЮЗ УЧЕНЫХ_31.10.15_10(19)» ebook=»yes» ]