
Modern technology allow the computer to implement a dialogue with the user in natural language. So called voice dialogue systems have the following features: speech recognition and understanding, dialogue management, the formation of the speech flow. Any dialogue system is built on the recognition of sound data from the speaker. Sound wave-vector can comprise different amount of features: the angular frequency, oscillation amplitude, oscillation frequency, sound wavelength, sound intensity, sound pressure, etc. The main difficulty for good working dialog systems lies in the processing of large amounts of data. Each feature is the vector consisting of a set of points that describe the behavior of the sound wave. All data may have consequences of effects such as noise (natural factor), voice distortion (human factor), the attributes may have a low level of variation. Therefore, an important step in the processing of acoustical signal is a selection of informative features. Standard methods for extraction informative features some times do not show high efficiency if data has a large size. Therefore is necessary step to involve existing methods or to develop new methods, for example, based on intelligent information technology (IIT). At the present time, data analysis systems based on the Intelligent Information Technologies (IIT) became more popular in many sectors of human activity. Therefore became more urgent question of the development methods for automatic design and adaptation IIT for specific tasks such as feature selection. Necessary to eliminate expensive design of IIT and reduce the time, which is required for the development of intelligent systems. One of the most perspective and popular technology is an artificial neural networks (ANN). The range of tasks which are solved by artificial neural networks is wide (classification, prediction). In this article the new approach using multi-criteria genetic programming for modeling artificial neural network (ANN) classifiers in the task of feature selection (SelfAGP+ANN) was proposed. Using «Self-adjusting» procedure for evolutionary algorithm allows to choose the optimal combination of evolution operators (EO) automatically. Thence, to reduce the computational resources and requires to an end user.
For realization acoustical feature selection task a two data bases in Krasnoyarsk city on the recording studio «WAVE» in 2014 year was created. For recognition a human`s age the data base RSDB — A (Eng. Russian Sound Data Base — Age) was created, which consists of voices of people from 14 to 18 and from 19 to 60 years old. For recognition the human`s gender the data base RSDB — G (Eng. Russian Sound Data Base — Gender) was created, which consists of voices of both human`s gender (man, woman) (Table 1). The processing of feature extraction from the sound recorders by following software packages: Notepad ++, Praat («script») «Цитата» [2, p. 15], Excel 97-2003 was realized. All described data bases have «full» sets of features.
Table 1.
Used data bases description
| Data base name | Language | Volume of data base | Amount of features | Name of classes |
| RSDB – A | Russian | 800 | 50 | Adult,Underage |
| RSDB – G | Russian | 800 | 50 | Man, Woman |
Proposed algorithm SelfAGP is based on genetic programming (GP) algorithm. Genetic programming to solve a wide range of tasks is used: the task of symbolic regression analysis, optimization, etc. For using GP technology is necessary to code objects in the form of a tree. The tree is a directed graph consisting of nodes and end vertex (leaves). Nodes is a multiplicity F {+, <}, which is consists of two types of mathematical operators), and the leaves are composed from multiplicity T {IN1, IN2, IN3,…, INn — input blocks (feature set from data base), F1, F2, F3, F4 …, Fn — activation functions (neurons)} (figure 1). Operator «+» from multiplicity F indicates formation all neurons in one layer and operator «<» indicates formation all layers in ANN. The amount of the input blocks in ANN consist of set size of features «Цитата» [5, p. 340].
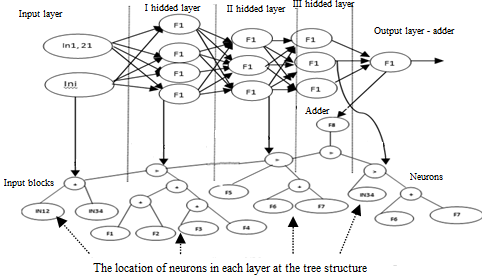
Figure 1. Tree type of neural network model structure
For realization a feature selection task was used multi-criteria approach. For estimation accuracy is used neural network classifiers. A general schema for realization algorithm is the following:
Step 1. Creating a population of individuals. Each individual is a tree — ANN.
Step 2. Optimization of the neural network weighting factors by one-criteria the genetic algorithm (GA). The criteria for stopping the GA is the maximum value of classification accuracy.
Step 3. Choosing evolutionary operators. All combinations of the EO have an equal probabilities of being selected in this step. In other step is necessary to recalculate new combinations of EO. All combinations of EO were formed with different types of operators. There are two types of selection operators (tournament, proportion), two types of mutation operators (strong, weak) and one type for recombination (one-point) were used.
Step 4. Estimation individuals by fitness functions:
- The first criteria is the value of the pair correlation. The fitness function is calculated by formula (1):

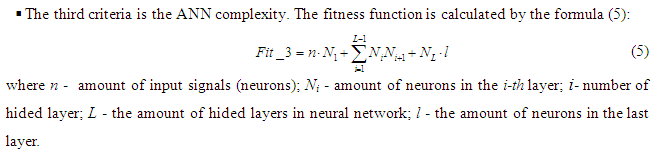
Step 5. Selection two parents for recombination by VEGA (Vector Evaluated Genetic Algorithm) method. The selection is based on the suitability of individuals by each of the K criteria separately. Therefore, the intermediate population with equal portions of individuals is filled, which are selected by each of the criteria type. The VEGA «Цитата» [1, p. 43] method for selection intermediate population is following:

Step 6. Recombination of two selected individuals.
Step 7. Mutation of descendant.
Step 8. Evaluation new descendant.
Step 9. Choosing a new combination of EO. The efficiency of EO on the previous steps by the formula (6) is calculated:

The number of added fitness functions may be different, it depends on the algorithm. After comparing values ![]() of EO combinations, the variant of EO with highest value becomes a «priority» option and its probability increasing on 0.05. A combination of EO with the lowest probability value changes on the «priority» variant. The recalculation of probabilities at each iteration of the algorithm is realized. If all combinations on a «priority» option have been placed, all probability values clear and «Self — adjusting» procedure repeats (step 1). A new variants of EO combination again are generated.
of EO combinations, the variant of EO with highest value becomes a «priority» option and its probability increasing on 0.05. A combination of EO with the lowest probability value changes on the «priority» variant. The recalculation of probabilities at each iteration of the algorithm is realized. If all combinations on a «priority» option have been placed, all probability values clear and «Self — adjusting» procedure repeats (step 1). A new variants of EO combination again are generated.
Step 10. If the algorithm reached the predetermined value of accuracy or exhausted the computational resources — go to step (11), otherwise go to step (2).
Step 11. Choose the «best» (the most efficiency) individual.
The «best» individual is the ANN with optimal set of input values (set of features). After proposed algorithm working the initial set of features have been update. New set of features «shortened» are called.
For comparison the effectiveness on the «full» and «shortened» sets of features the following classifiers were chosen:
— Support Vector Machine — SVM, which was used for training method of sequential minimal optimization George. Platt;
— Simple Logistic;
— Naive Bayes Kernel classifier;
— Sequential Minimal Optimization (SMO);
— Additive Logistic Regression — Rule Induction;
To improve the accuracy of each classifier the algorithm «Optimization Parameter (Evolutionary)» was applied, which bases on the optimization parameters of classifier by one-criteria GA. The optimized parameters are represented in Table 2.
Table 2.
Parameters of the classifiers
| Classifier |
Parameters |
|
Naive Bayes Kernel |
application_grid_size; number_of_kernels; minimum_bandwidth |
|
SMO |
V – the amount of layers for the internal cross-checking; C – coefficient of retraining; M – the logistic model |
|
Simple Logistic |
I – amount of iteration |
|
Rule Induction |
Pureness; sample_ratio |
The starting installation for proposed algorithm are following: maximum number of layers in ANN — 8, number of neurons in each layer in ANN — 5, maximum number of individuals — 80. Each data base for test and train in proportion 80% / 20% respectively were divided. Table 3 contains the relative classification accuracy after 20 runs for all set of features.
Table 3.
Experimental results
|
Classifier |
Accuracy, %
(«full» data base) |
Accuracy, %
(«shortened» data base)
|
Difference, % |
Accuracy, %
(«full» data base) |
Accuracy, %
(«shortened» data base) |
Difference, % |
|
RSDB-A |
RSDB-A | RSDB-G |
RSDB-G |
|||
| SMO | 95,01 | 96,87 | 1,77 | 95,56 | 95,2 | 0,36 |
| Simple Logistic | 94,12 | 94,92 | 0,8 | 94,16 | 94,3 | 0,14 |
| Rule Induction | 91,22 | 93,16 | 1,94 | 92 | 93,1 | 1,1 |
| Naive Bayes Kernel | 95,01 | 96 | 0,99 | 94,5 | 94,87 | 0,37 |
The algorithm with Visual Studio C # was realized. All tests on a laptop with 1 terabyte of memory and the four-core processor Intel Core i5-2410 (2.10 GHz) were done. Also for realization research test with different types of classifiers Rapid Miner v. 5.3 [3, p. 80] software with additional source Weka was used «Цитата» [4, p. 5].
In the conclusion of the research in this paper should to say, that the described algorithm SelfAGP+ANN for future selection good results is shown. An accuracy of used classifiers with «shortened» features set in general is better, than with «full» features set. The difference between accuracy results are more than 0,14, but less than 2. An evolutionary algorithm (GP) with design of neural network can be applied in different area of optimization tasks (problems), also in the task of feature selection. The reduction of features in all data bases was on average from 50 to 30 for the RSDB-A and for the RSDB-G — from 50 to 26 attributes. According to the research it can be concluded that the developed approach shows optimal result after test, what is confirmed in the Table 3. This algorithm allows to find relevant features set by applying compact and accurate neural networks. This approach is useful for those category of tasks, also can be useful to implement in dialog system and to improve their efficiency.
References:
- Ashish G., Satchidanada D. Evolutionary Algorithm for Multi-Criterion Optimization: A Survey. International Journal of Computing & Information Science, Vol. 2, No. 1.
- Boersma P. Praat, a system for doing phonetics by computer. Glot international, 5(9/10), 2002.
- Fareed Akthar, Caroline Hahne. Rapid Miner 5: Operator reference// Dortmund, 2012.
- Hall M. [et al.]. The WEKA Data Mining Software: An Update, SIGKDD Explorations. 2009. Vol. 11, iss. 1.https://modis.ispras.ru/seminar/wp-content/uploads/2012/07/Coursework.pdf.
- Loseva E.D., Lipinsky L.V. Ensembles of neural network classifiers using genetic programming multi-criteria self-configuring // Actual problems of aviation and cosmonautics: Sat. abstracts. 2015. Part 1.[schema type=»book» name=»MULTI-CRITERIA SELF-ADJUSTING GENETIC PROGRAMMING FOR DESIGN NEURAL NETWORK MODELS IN THE TASK OF FEATURE SELECTION » description=»A new approach for selection of informative features is represented. The new method on the multi-criteria «Self-adjusting» genetic programming with modeling of the neural network classifiers is described. Each neural network model automatically form using evolutionary procedure and their effectiveness by some criteria were estimated. The initial (full set of features) and new data base (reduced set of features) in the task of recognition human`s gender and age were tested. After applying proposed method the improvement of the accuracy is observed. » author=»Loseva Elena» publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2016-12-27″ edition=»euroasia-science.ru_26-27.02.2016_2(23)» ebook=»yes» ]