
Введение.
Методы машинного обучения на основе сжатия описания начальной прецедентной информации стали привлекать внимание исследователей в области теоретической информатики и разработчиков интеллектуализированного программного обеспечения после появления парадигмы MDL – minimum description length [5]. Эта парадигма основана на принципе «бритвы Оккама», согласно которому лучшей гипотезой для объяснения данных является та, которая соответствует наибольшему их сжатию. Под сжатием данных понимается процесс, который приводит к уменьшению объёма данных без потери возможности их использования для получения целевой информации. Теоретической основой и математическим обоснованием построения теории обучения (эмпирической индукции) на основе сжатия явились работы Р. Соломонова и А. Н. Колмогорова [4,6].
Кроме достаточно строго обоснованных теоретических методов, базирующихся на принципах сжатия обучающей информации, известны эвристические подходы к построению алгоритмов машинного обучения на основе «простой структурной закономерности», например, представленные в работе Н. Г. Загоруйко [7], и на поиске кратчайших отделителей – тупиковых тестов и их обобщениях – в работах Ю.И. Журавлёва [1].
Целью этой статьи является дальнейшее изучение теоретических вопросов машинного обучения на основе сжатия начальной прецедентной (обучающей) информации и применения методов теории колмогоровской сложности.
- Декомпрессоры и компрессоры
Определение 1. [3, с. 221] Колмогоровская сложность слова x при заданном способе описания – вычислимой функции (декомпрессоре) D есть ![]() , если существует слово p такое что D( p ) — x. В противном случае полагается, что значение сложности не ограничено (+∞), и говорят, что колмогоровская сложность не определена. □
, если существует слово p такое что D( p ) — x. В противном случае полагается, что значение сложности не ограничено (+∞), и говорят, что колмогоровская сложность не определена. □
Здесь и далее l(x) означает длину слова x.
Определение 2. Условная колмогоровская сложность слова x при заданном слове y есть ![]() . Если y – пустое слово, то
. Если y – пустое слово, то ![]() .
.
Определение 3. Говорят, что декомпрессор D1 слова x не хуже декомпрессора D2, если ![]() . Декомпрессор называют оптимальным, если он не хуже любого другого декомпрессора.
. Декомпрессор называют оптимальным, если он не хуже любого другого декомпрессора.
Теорема 1 (Соломонова–Колмогорова) [3]. Существуют оптимальные декомпрессоры. □
Далее запись KS(x) (или KS(x⌈y)) будет обозначать колмогоровскую сложность (условную сложность) строки по некоторому оптимальному декомпрессору.
Теорема 2 (Колмогоров). Пусть A – перечислимое множество пар (x, a) и ![]() . Тогда
. Тогда
![]()
Теорема 3. [2, с. 75] Колмогоровская сложность конечной строки x как величина ![]() определена тогда и только тогда, когда существует машина Тьюринга
определена тогда и только тогда, когда существует машина Тьюринга ![]() (компрессор) такая, что
(компрессор) такая, что ![]() .
.
Определение 4. Пусть x – конечная строка, и множество её компрессоров ![]() не является пустым. Назовем
не является пустым. Назовем
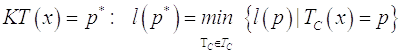
сжатием строки наилучшим компрессором.
Теорема 4 [2, с. 75]. Словарная функция KT (x) сжатия наилучшим компрессором не является вычислимой.
- Сжатие обучающей информации.
Пусть ![]() – обучающая начальная прецедентная информация, где
– обучающая начальная прецедентная информация, где ![]() – векторы-описания объектов,
– векторы-описания объектов, ![]() – номер класса объекта
– номер класса объекта ![]() , принимающий (для упрощения в рамках этой статьи) только два значения: 0 и 1. Пусть каждая координата любого вектора
, принимающий (для упрощения в рамках этой статьи) только два значения: 0 и 1. Пусть каждая координата любого вектора ![]() использует ровно M бит памяти;
использует ровно M бит памяти; ![]() использует 1 бит памяти. Тогда длина обучающей информации составляет m(Mn + 1) бит, из которых mMn – затрачивается на описания объектов, а m бит – на вектор
использует 1 бит памяти. Тогда длина обучающей информации составляет m(Mn + 1) бит, из которых mMn – затрачивается на описания объектов, а m бит – на вектор ![]() . Следовательно, обучающую информацию можно представить двоичной строкой
. Следовательно, обучающую информацию можно представить двоичной строкой ![]() указанной длины. Обозначим
указанной длины. Обозначим ![]() – множество всевозможных компрессоров выборки.
– множество всевозможных компрессоров выборки.
Пусть P – такая строка, что существует машина Тьюринга T, которая для любого вектора ![]() , используя эту строку P, правильно вычисляет значение
, используя эту строку P, правильно вычисляет значение ![]() :
: ![]() . Такая строка называется сжатием обучающей выборки
. Такая строка называется сжатием обучающей выборки ![]() . По строке P, вообще говоря, может оказаться невозможным вычислить (восстановить) обучающую выборку, представленную строкой
. По строке P, вообще говоря, может оказаться невозможным вычислить (восстановить) обучающую выборку, представленную строкой ![]() , однако можно вычислить частичную функцию, ставящую в соответствие любому описанию произвольного примера из обучающей информации
, однако можно вычислить частичную функцию, ставящую в соответствие любому описанию произвольного примера из обучающей информации ![]() значение
значение ![]() .
.
Определение 5. Колмогоровская сложность обучающей информации, представленной строкой ![]() , относительно декомпрессора D есть
, относительно декомпрессора D есть
![]()
если существует хотя бы одно слово P, удовлетворяющее указанному условию. В противном случае полагается, что значение сложности не ограничено (+ ∞).
Определение 6. Пусть ![]() – строка, представляющая обучающую выборку, и множество её компрессоров
– строка, представляющая обучающую выборку, и множество её компрессоров ![]() не является пустым. Назовем величину
не является пустым. Назовем величину
![]()
сжатием обучающей выборки наилучшим компрессором. □
Подчеркнём, что сжатие ![]() заведомо гарантирует существование декомпрессора – машины Тьюринга D такой, что
заведомо гарантирует существование декомпрессора – машины Тьюринга D такой, что
![]()
Если обучающая выборка не является случайной (в таком случае, согласно теории Колмогорова, она содержит закономерности), то должно выполняться неравенство ![]() . В то же время по слову
. В то же время по слову ![]() можно вычислить значение
можно вычислить значение ![]() для любого вектора
для любого вектора ![]() . Следовательно, слово
. Следовательно, слово ![]() содержит не полное признаковое описание объектов, а сокращенное. Если ω
содержит не полное признаковое описание объектов, а сокращенное. Если ω![]() – сокращённое описание объекта
– сокращённое описание объекта ![]() , то это сокращённое описание «подходит» сразу для множества объектов, порождая таким образом обобщение на некоторое множество G(
, то это сокращённое описание «подходит» сразу для множества объектов, порождая таким образом обобщение на некоторое множество G(![]() ) объектов, элементы которого будут классифицироваться точно так, как объект
) объектов, элементы которого будут классифицироваться точно так, как объект ![]() . Этим объясняется способность сжатия к построению решающих правил, обеспечивающих обучаемость [2].
. Этим объясняется способность сжатия к построению решающих правил, обеспечивающих обучаемость [2].
В общем случае словарная функция ![]() не является вычислимой, поэтому поиск компрессора, близкого к наилучшему, осуществляется эвристическими методами. Причём с тем большим успехом, чем меньшей оказывается длина слова (сжатия), полученного выбранным компрессором. Это слово, как и оптимальное сжатие, далее также будем обозначать
не является вычислимой, поэтому поиск компрессора, близкого к наилучшему, осуществляется эвристическими методами. Причём с тем большим успехом, чем меньшей оказывается длина слова (сжатия), полученного выбранным компрессором. Это слово, как и оптимальное сжатие, далее также будем обозначать ![]() .
.
- Критерий остановки обучения на основе сжатия.
Принцип MDL гласит: наилучшая гипотеза для данного набора данных та, которая минимизирует сумму длины описания кода гипотезы (также называемой моделью) и длины описания множества данных относительно этой гипотезы. В рассматриваемой постановке слово ![]() является кодом гипотезы (будем также говорить – гипотезой
является кодом гипотезы (будем также говорить – гипотезой ![]() ), а длина части неправильно классифицируемых гипотезой объектов обучающей выборки является второй частью суммы, определённой принципом MDL. Иначе говоря, сложность обучающей выборки относительно гипотезы
), а длина части неправильно классифицируемых гипотезой объектов обучающей выборки является второй частью суммы, определённой принципом MDL. Иначе говоря, сложность обучающей выборки относительно гипотезы ![]() определяется частью выборки, «не объясняемой» этой гипотезой.
определяется частью выборки, «не объясняемой» этой гипотезой.
Если m – число примеров в обучающей выборке, а величину m(Mn + 1) принять в качестве длины её описания, то сложность одного необъяснённого примера составит Mn + 1. Процесс обучения характеризуется поэтапным усложнением гипотезы, которая классифицирует объекты выборки, по мере необходимости исправлять неправильную классификацию некоторых примеров. Поэтому сложность синтезируемой таким образом гипотезы растет: ![]() , где 1, 2, …, t – шаги коррекции. При этом число ошибочно классифицированных примеров выборки убывает:
, где 1, 2, …, t – шаги коррекции. При этом число ошибочно классифицированных примеров выборки убывает: ![]() .
.
Критерий остановки процесса обучения определяется значениями суммы ![]() и определяется шагом
и определяется шагом ![]() , где g величина может быть, например, взята равной Mn + 1. Заметим, что минимум этой суммы может достигаться при нулевом количестве ошибок классификации обучающей выборки, что будет говорить об удачном выборе семейства, из которого извлекается гипотеза.
, где g величина может быть, например, взята равной Mn + 1. Заметим, что минимум этой суммы может достигаться при нулевом количестве ошибок классификации обучающей выборки, что будет говорить об удачном выборе семейства, из которого извлекается гипотеза.
Для реализации указанного критерия необходимо научиться оценивать величину удлинения описания гипотезы на шагах коррекции. В некоторых случаях, например, для решающих деревьев, это сделать сравнительно легко. Для параметрических моделей, в частности, для нейронных сетей фиксированной структуры, можно оценивать усложнение гипотезы увеличивающейся величиной максимального модуля параметров, а при растущей структуре сети – оценкой длины описания добавляемых элементов.
Список литературы:
- Дмитриев А.Н., Журавлев Ю.И., Кренделев Ф.П. О математических принципах классификации предметов и явлений // Дискретный анализ. Новосибирск: ИМ СО АН СССР. 1966. Вып. 7. С. 3 – 11.
- Донской В.И. Алгоритмические модели обучения классификации: обоснование, сравнение, выбор. Симферополь: ДИАЙПИ, 2014. 228 с.
- Колмогоров А.Н. Теория информации и теория алгоритмов. М.: Наука, 1987. 304 с.
- Колмогоров А.Н. Три подхода к определению понятия «количество информации» // Проблемы передачи информации. N.1. №1. С. 3–11.
- Rissanen, J. Modeling by shortest data description // Automatica. 1978. 14 (5). P. 465–658.
- Solomonoff J. A Formal Theory of Inductive Inference. Part I // Information and Control. 1964. 7 (1). P. 1–22.
- Zagoruiko N.G., Samochvalov K.F. Hypotheses of the Simplicity in the Pattern Recognition: Proc. of Second Int. Joint Conf. on Artificial Intelligence. London: William Kaufmann, 1971. P. 318-321[schema type=»book» name=»МАШИННОЕ ОБУЧЕНИЕ И СЖАТИЕ ПРЕЦЕДЕНТНОЙ ИНФОРМАЦИИ» description=»Целью этой статьи является изучение теоретических вопросов машинного обучения на основе сжатия начальной прецедентной (обучающей) информации. Для достижения этой цели используются методы теории колмогоровской сложности. Даны определения сложности обучающей информации. Показано, как процесс построения гипотезы, основанной на сжатии обучающей информации, обеспечивает возможность эмпирического обобщения и достижения обучаемости. Предложен критерий остановки процесса машинного обучения на основе сжатия. Для реализации указанного критерия необходимо научиться оценивать величину удлинения описания гипотезы на шагах коррекции. В некоторых случаях, например, для решающих деревьев, это сделать сравнительно легко. Для параметрических моделей, в частности, для нейронных сетей фиксированной структуры, можно оценивать усложнение гипотезы увеличивающейся по мере обучения величиной максимального модуля параметров, а при растущей структуре сети – оценкой длины описания добавляемых элементов.» author=»Донской Владимир Иосифович» publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2016-12-26″ edition=»euroasia-science.ru_26-27.02.2016_2(23)» ebook=»yes» ]