
С появлением вычислительной техники объём данных, с которыми может работать человек, значительно увеличивается, а следовательно и обработка информации затрудняется. Выйти из этого положения можно обрабатывая только часть данных, отвечающую некоторым характеристикам, а не весь объем информации. Кластеризация позволяет разделить все данные на группы, все элементы которых будут схожи друг с другом по какому-либо признаку. Это применимо в очень широком спектре научных областей: статистике, финансовой математике, оптимизации, в информационных технологиях для анализа данных и др. Таким образом, задача кластеризации актуальна в современном мире и играет значительную роль при обработке больших объемов данных.
Кластеризация (кластерный анализ) – это задача разбиения множества объектов на группы, называемые кластерами [1, стр. 7]. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Кластеризация может иметь различные цели, определяемые особенностью конкретной задачи. К основным целям относятся: понимание данных – определение структуры множества данных, путем разбиения его на группы схожих объектов; обнаружение новизны – выделение объектов, не подходящих ни к одному из кластеров; сжатие данных, когда рассматриваются не целые классы данных, а лишь типичных представителей классов.
Применение кластерного анализа в общем виде сводится к следующим этапам [1, стр.15]: 1 этап – отбор выборки объектов для кластеризации; 2 этап – определение множества переменных, по которым будут оцениваться объекты в выборке; 3 этап – вычисление значений меры сходства между объектами; 4 этап – применение метода кластерного анализа для создания групп сходных объектов (кластеров); 5 этап – представление результатов анализа.
Постановка задачи кластеризации.

Все алгоритмы кластеризации можно отнести к двум классам [1 стр.49]:
- Иерархические и плоские.
Иерархические алгоритмы строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. При этом на выходе получается дерево кластеров, корнем которого является вся выборка, а листьями – наиболее мелкие кластеры. Эти алгоритмы также имеют два основных типа:
- нисходящие алгоритмы: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры.
- восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные.
Плоские алгоритмы строят одно разбиение объектов на кластеры.
- Четкие и нечеткие.
Четкие (непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, которому он принадлежит. Нечеткие (пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам.
Основной задачей при кластеризации является определение расстояний между внутрикластерными объектами. Существует множество методов определения расстояний между объектами, основные из них представлены в таблице 1 [2, стр.31].
Таблица 1.
Метрики для определения расстояний между объектами

Существуют различные правила, называемые методами объединения или связи объектов в кластеры.
- Метод ближайшего соседа или одиночная связь (single linkage). В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки.
- Метод наиболее удаленных соседей или полная связь (complete linkage). Расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (наиболее удаленными соседями).
- Метод Варда (Ward’s method). В качестве расстояния между кластерами берется прирост суммы квадратов расстояний объектов до центров кластеров, получаемый в результате их объединения.
- Метод невзвешенного попарного среднего (unweighted pair-group method using arithmetic averages, UPGMA). В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Он эффективен, когда объекты формируют различные группы.
- Метод взвешенного попарного среднего (weighted pair-group method using arithmetic averages, WPGMA). Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров используется в качестве весового коэффициента, поэтому должны использоваться неравные размеры кластеров.
- Невзвешенный центроидный метод (unweighted pair-group method using the centroid average UPGMC). В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести.
- Взвешенный центроидный метод (weighted pair-group method using the centroid average, WPGMC). Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров.
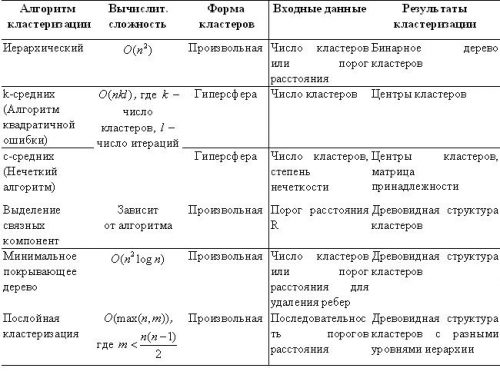
Все перечисленные методы кластеризации характеризуются следующими параметрами: вычислительная сложность, форма кластеров, входные данные, результаты кластеризации, которые сведены в таблицу для рассмотренных выше методов. Данные показатели приведены в таблице 2.
Методы, рассмотренные в таблице 2, являются классическими алгоритмами кластерного анализа. Основным критерием, по которому оценивается алгоритм кластеризации – качество кластеризации [2, стр.43].
Таблица 2.
Параметры, характеризующие методы кластеризации
В связи с появлением сверхбольших баз данных, появились новые требования, которым должен удовлетворять алгоритм кластеризации. К этим требования относится: масштабируемость; независимость результатов от порядка входных данных; независимость параметров алгоритма от входных данных. В последнее время ведутся активные разработки новых алгоритмов кластеризации, способных к масштабируемости и обработке сверхбольших баз данных [3, стр 126-134, 4].
Алгоритм BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies). В алгоритме реализован двухэтапный процесс кластеризации: формирование предварительный набор кластеров; применение к выявленным кластерам других алгоритмов кластеризации.
Алгоритм CLARA (Clustering LARge Applications) извлекает множество образцов из БД и кластеризация применяется к каждому из образцов. Эффективность алгоритма зависит от выбранного в качестве образца набора данных.
Алгоритм Clarans (Clustering Large Applications based upon RANdomized Search). В результате работы алгоритма совокупность узлов графа представляет собой разбиение множества данных на число кластеров, определенное пользователем. Происходит сортировка всех возможных разбиений множества данных в поисках приемлемого решения. Поиск решения останавливается в том узле, где достигается минимум среди предопределенного числа локальных минимумов.
Алгоритм FTCA (Fast Threshold Clustering Algorithm). На первом этапе происходит сортировка всех объектов по их средней корреляции с остальными объектами в порядке возрастания. На следующем этапе происходит создание кластеров, используя Treshold, границу выше которой объекты считаются похожими достаточно, чтобы быть вместе, в одной группе.
В среде Matlab реализованы два алгоритма: FOREL и метод полной связи.

Выводы.
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин:
- не существует однозначного критерия качества кластеризации. Вместе с тем, ряд алгоритмов, не имеющих чётко выраженного критерия, осуществляют достаточно хорошую кластеризацию для заданной предметной области;
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием;
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом.
Список литературы:
- Айвазян, В.М. Прикладная статистика: классификация и снижение размерности / В.М. Айвазян [и др.]. – М.: Финансы и Статистика, 1989. – 607 с.
- Мандель, И.Д. Кластерный анализ / И.Д. Мандель. – М.: Финансы и Статистика, 1988. – 176 с.
- Загоруйко, Н.Г. Прикладные методы анализа данных и знаний / Н.Г. Загоруйко. – Новосибирск: Издательство Института математики, 1999. – 261 с.
- Jain, A.K. Data Clastering: A Review / A.K. Jain, M.N. Murty, P.J. Flynn – [Электронный ресурс]. – Режим доступа: https://www.cs.tau.ac.il/~fiat/DataMine05/p264-jain.pdf [Дата обращения 18.11.2014].[schema type=»book» name=»РЕАЛИЗАЦИЯ АЛГОРИТМОВ КЛАСТЕРИЗАЦИИ В СРЕДЕ MATLAB» author=»Яковлев Алексей Вячеславович, Васюкова Екатерина Олеговна, Пеливан Михаил Анатольевич» publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2017-06-19″ edition=»ЕВРАЗИЙСКИЙ СОЮЗ УЧЕНЫХ_ 30.12.2014_12(09)» ebook=»yes» ]