

Сканирование выполняется с целью определить, какие порты целевого хоста закреплены за приложениями. Сканирование – это подготовительная операция, разведка периметра сети. После того, как будет составлен список активных («открытых») портов, начнётся выяснение — какие именно приложения используют эти порты.
После определения приложений, а иногда даже их версий, фаза разведки заканчивается, и начинается фаза активных действий злоумышленника — атака. Не обязательно, что после первой фазы (разведки) сразу начнётся вторая. Зачастую через некоторое время разведка повторяется, причём с других узлов сети. Это своего рода проверка бдительности «стражи» — администраторов. Атака может так и не начаться, если не обнаружено ни одной потенциально уязвимой точки воздействия. Следует понимать, что сканирование само по себе ничем не может повредить сети — повредить могут последующие действия, если они последуют.
Были проанализированы следующие типы сканирования портов:
- Проверка онлайна
- SYN-сканирование
- TCP-сканирование
- UDP-сканирование
- ACK-сканирование
- FIN-сканирование
Все они на данный момент активно используются при исследовании удаленных хостов.
Основными последствиями сканирования портов являются:
- Имя хоста,
- Получение списка открытых портов,
- Получение списка закрытых портов,
- Получение списка сервисов на портах хоста,
- Предположительное определение типа и версии ОС.
Таким образом, злоумышленник после успешного сканирования портов жертвы, имеет полную и достаточную информацию о ПЭВМ, чтобы суметь воспользоваться изъянами данной машины. Защита от сканирования является актуальной и важной проблемой среди как системных администраторов и специалистов в защите информации, так и «продвинутых» пользователей ПК.
После анализа типов сканирования были рассмотрены методы защиты от сканирования портов. Основными методами защиты являются:
- nt – метод: при работе данного метода происходит вычисление метрики, определяющей соотношение N подозрительных событий за время наблюдения T;
- sa – метод: основан на последовательном анализе — способе проверки статистических гипотез, при котором необходимое число наблюдений не фиксируется заранее, а определяется в процессе самой проверки.
Рассмотрим каждый метод немного подробнее.
Nt — метод.
NT-метод показывает хорошие результаты в случае массированного, методичного сканирования. Однако правильный выбор порога является камнем преткновения. Выявление сканеров, которые посылают запросы в случайном темпе или используют большие временные задержки в своей работе, также является проблемой, поскольку такое поведение невозможно выявить с помощью N/T метрики. Возникает необходимость в более изощренных методах выявления аномального поведения сетевых устройств. Далее предполагается, что известно «нормальное» состояние сети, т. е. распределение вероятностей обращений к активным сетевым устройствам и сервисам. Например, вероятности обращений к адресу P(dst_ip), порту P(dst_port) или совместная вероятность P(dst_ip, dst_port). Тогда если устройство с адресом src_ip обращается к какому-либо устройству с адресом dst_ip и использует в качестве порта назначения dst_port, а P(dst_ip, dst_port) мала, то устройство попадает в число подозреваемых. Основная трудность состоит в том, какие именно вероятности, условные вероятности и совместные вероятности хранить, тем более что нужно собирать информацию в течение длительного периода времени.
Предполагается, что априори известно распределение нормального трафика защищаемой сети по хостам и портам, т. е. если в пакете встречается данная комбинация , то известна вероятность ее появления . Определим индекс аномальности пакета (или события), содержащего пару х через отрицательный логарифм правдоподобия:
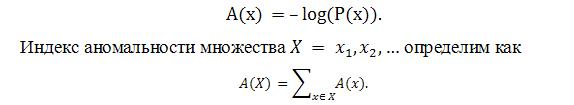

Таким образом, чем больше необычных комбинаций использует сканер, тем быстрее он будет обнаружен. Заметим, что здесь игнорируется тот факт, что распределение вероятностей зависит от времени суток. Поэтому для сканеров, функционирующих в разное время, индекс аномальности рассчитывается, по существу, относительно разных распределений.
SA – метод.
Пусть Х – случайная величина, а x1,…,xn – последовательность независимых и одинаково распределенных наблюдений за Х. Допустим, что относительно этого распределения имеется два предположения. Гипотеза H0 – наблюдения распределены с плотностью р0(х), а гипотеза H1 – наблюдения распределены с плотностью р1(х). После каждого наблюдения предоставляется выбор из трех возможных решений: принять H0 и закончить наблюдения, принять H1 и закончить наблюдения, не принимать ни одну из гипотез и продолжить наблюдения.
Решающая процедура δ* определяется следующим образом. Фиксируются два порога: верхний A и нижний B, такие что 0 < B < A. Пусть выполнено n наблюдений (n = 1, 2, …). Обозначим через отношение правдоподобия:




В-третьих, формулами для вычисления среднего числа наблюдений, которые зависят от параметров р0(х), р1(х), α и β.
Таким образом, задав параметры α, β, р0 и р1 можно построить алгоритм принятия той или иной гипотезы за конечное число шагов.
В ходе дальнейшего исследования, будет разработан программный комплекс, в котором будут реализованы два метода обнаружения сканирования портов, описанных выше, и выявлен наиболее эффективный посредствам сравнительного анализа по следующим критериям:
- Ошибки первого/второго рода;
- Количество обработанных данных;
- Нагрузка на процессор;
- Скорость обработки данных;
- Место, занимаемое временными файлами на жестком диске;
- Совместимость с различными ОС;
- Отказоустойчивость(при большом кол-ве соединений).
Именно такие критерии могут всеобъемлюще охарактеризовать и наглядно показать различия в методах обнаружения сканирования портов.
Список литературы:
- Ананьин Е.В., Кожевникова И.С., Датская Л.В. Анализ угроз, связанных со сканированием портов: статья, 2015.
- С. В. Бредихин, В. И. Костин, Н. Г. Щербакова Обнаружение сканеров в ip-сетях методом последовательного статистического анализа: статья,
- Gordon L. NMAP Network Scanning: The Official NMAP Project Guide to Network Discovery and Security Scanning. 2009. P. 468.[schema type=»book» name=»КРИТЕРИИ ОЦЕНКИ ЭФФЕКТИВНОСТИ МЕТОДОВ ОБНАРУЖЕНИЯ СКАНИРОВАНИЯ ПОРТОВ ЗЛОУМЫШЛЕННИКОМ» description=»Рассматриваются современные методы сканирования портов. Приведен обзор методов, применяемых для обнаружения сканирования портов и статистических моделей выявления аномального трафика. Особое внимание уделяется методу последовательного анализа и моделям, использующим этот метод для выявления сканеров. Выбраны наиболее подходящие критерии оценки методов.» author=»Ананьин Евгений Викторович, Кожевникова Ирина Сергеевна, Датская Лариса Викторовна» publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2017-03-12″ edition=»ЕВРАЗИЙСКИЙ СОЮЗ УЧЕНЫХ_30.05.2015_05(14)» ebook=»yes» ]