

Одним из наиболее популярных при статистическом анализе данных является критерий Пирсона. Хи-квадрат критерию Пирсона полностью посвящена первая часть рекомендаций Госстандарта [1], тогда как все остальные критерии описаны во второй части рекомендаций [2]. Наиболее популярные критерии проверки гипотез даны в таблице 1 [3].
Таблица 1.
Наиболее популярные статистические критерии


Из таблицы 1 видно, что работа по созданию различных статистических критериев продолжается уже более 100 лет. Создано большое число статистических критериев, которые дополняют друг друга. Однако работу по созданию многообразия критериев нельзя считать законченной. К сожалению, хи-квадрат критерий для надежных оценок с доверительной вероятностью 0.99 требует иметь тестовую выборку порядка 400 опытов. Для биометрии это неприемлемо, так как обучение и тестирования нейросетевых преобразователей биометрия-код идет на выборках примерно из 20 примеров.
Требования к размеру тестовой выборки может быть снижено, если использовать более эффективные статистические критерии (лучше, чем другие известные критерии). В связи с этим актуальной задачей является дополнение уже найденных критериев новыми.
Следует подчеркнуть, что хи-квадрат критерий (строка 1, таблица 1) можно рассматривать как критерий нормированного среднего арифметического квадратов отклонения. На ряду с критерием среднего арифметического может быть построен критерий среднего геометрического сравниваемых между собой функций вероятности:
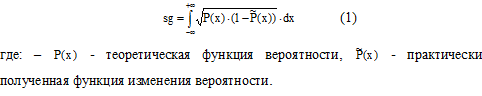

При организации численного эксперимента будем исходить из того, что должны проверяться две статистические гипотезы. Первая гипотеза состоит в том, что данные тестовой выборки имеют нормальный закон распределения значений. Вторая гипотеза состоит в том, что данные этой же выборки могут иметь нормальный закон распределения значений. Как следствие, при организации численного эксперимента необходимо использовать два программных генератора псевдо случайных данных, как это показано на блок-схеме рисунка 1.


Рисунок 1. Блок-схема организации численного эксперимента по оценке мощности одномерного критерия хи-квадрат
Каждый из генераторов случайных данных Г1 (нормальные данные) и Г2 (данные с равномерным законом распределения) случайным образом подаются на вход вычислителя значения хи-квадрат критерия (1). Далее значения хи-квадрат критерия должны сравниваться с некоторым порогом квантователя. Если значение хи-квадрат менее порога, то принимается решение о нормальности исследуемых входных данных. Если значение хи-квадрат критерия (1) оказывается выше или ниже порога, то принимается решение о наибольшей справедливости одной из гипотез.


Рисунок 2. Плотности распределения значений для нормального и равномерного законов распределения значений для критерия среднего геометрического значения
Проведенный численный эксперимент показал, что новый критерий среднего геометрического на выборках от 25 до 49 опытов оказывается примерно в два раза мощнее классического хи-квадрат критерия. При проверки гипотезы нормальности законно распределения биометрических данных удается примерно в 2 раза снизить вероятности ошибок первого и второго рода. Данные о равных вероятностях ошибок первого и второго рода приведены в таблице 2.
Таблица 2.
Значения равных вероятностей ошибок первого и второго рода при проверке гипотезы нормального и гипотезы равномерного закона распределения значений
|
Число опытов в тестовой выборке |
|||||||||||||||||||
| 9 | 16 | 25 | 36 | 49 | 64 | 81 | 100 | 121 | |||||||||||
|
Значения равновероятных ошибок Р1=Р2=РЕЕ |
|||||||||||||||||||
| Критерий Джини
1941 г. |
0.50 |
0.497 |
0.482 |
0.417 |
0.348 |
0.269 |
0.225 |
0.205 |
0.186 |
||||||||||
| Критерий Смирнова-Колмагорова
1933 г. |
0.46 |
0.44 |
0.345 |
0.315 |
0.239 |
0.232 |
0.215 |
0.201 |
0.177 |
||||||||||
| Критерий Фроцини
1978 г. |
0.439 | 0.38 | 0.325 | 0.268 | 0.212 | 0.172 | 0.154 | 0.107 | 0.089 | ||||||||||
| Хи-квадрат критерий Пирсона
1900 г. |
0.42 |
0.32 |
0.29 |
0.256 |
0.207 |
0.153 |
0.131 |
0.101 |
0.083 |
||||||||||
| Среднее геометрическое 2015 г. |
0.414 |
0.331 |
0.238 |
0.166 |
0.113 |
0.058 |
0.034 |
0.017 |
0.012 |
||||||||||
| Критерий Крамера-фон Мезиса
1928 г. |
0.356 |
0.306 |
0.240 |
0.215 |
0.155 |
0.121 |
0.102 |
0.082 |
0.061 |
||||||||||
| ::::::::::::::::::::::: | ::::: | :::::: | :::::: | :::::: | :::::: | :::::: | ::::::: | :::::: | :::::: | ||||||||||
| Дифф. критерий Джини
2006 г. |
0.281 |
0.202 |
0.162 |
0.101 |
0.07 |
0.05 |
0.03 |
0.02 |
0.01 |
||||||||||
| ::::::::::::::::::::::: | ::::: | ::::::: | ::::::: | :::::: | :::::: | :::::: | ::::::: | ::::::: | :::::: | ||||||||||
Очевидно, что статистики среднего геометрического и среднего арифметического взаимно дополняют друг друга. В этом отношении новый критерий (1), видимо будет еще более эффективным если его рассматривать в совокупности с хи-квадрат критерием (би-критериальная оценка достоверности).
Предположительно в ближайшем будущем будут использоваться мультикритериальные статистические оценки, когда при проверке одной или нескольких статистических гипотез будут использоваться два и более критериев. Выбор совокупности статистических критериев должен исходить из условия их существенной независимости (слабой коррелированности). Чем слабее связаны оказываются статистические критерии, используемые в паре, тем эффективнее будет их совместная работа. То есть необходимо не только расширять номенклатуру статистических критериев, но подбирать из них наиболее эффективные группы (пары, тройки, четверки,…). Простой оценки мощности статистических критериев (таблица 2) недостаточно. Необходимо инициировать работы по исследованию совместимости статистических критерием и поиску оптимальных правил их объединения.
Формальной оценкой коррелированности критериев является их испытание по блок схеме рисунка 1 при одинаковых порогах заданной достоверности и при воздействии одной и той же выборкой случайных данных. Тогда математическое ожидание коэффициента коррелированности выходных кодов можно оценить по нормированному расстоянию Хэмминга между ними:
![]()

где: – h – расстояние Хэмминга между сравниваемыми кодами длинной – n, — расстояние Хэмминга между кодами, один из которых инвертирован.
Список литературы:
- Р 50.1.037-2002. Рекомендации по стандартизации. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа χ2. Госстандарт России. – Москва: 2001. — 140 с.
- Р 50.1.037-2002. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть II. Непараметрические критерии. Госстандарт России. Москва: 2002. — 123 с.
- Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. — Москва: Изд-во ФИЗМАТЛИТ, 2006. — 816 с.
- Малыгин А.Ю., Волчихин В.И., Иванов А.И., Фунтиков В.А. Быстрые алгоритмы тестирования нейросетевых механизмов биометрико-криптографической защиты информации. – Пенза: Изд-во Пензенского государственного университета, 2006. — 161 с.[schema type=»book» name=»РАСШИРЕНИЕ МНОГООБРАЗИЯ СТАТИСТИЧЕСКИХ КРИТЕРИЕВ, ИСПОЛЬЗУЕМЫХ ПРИ ПРОВЕРКЕ ГИПОТЕЗ РАСПРЕДЕЛЕНИЯ ЗНАЧЕНИЙ БИОМЕТРИЧЕСКИХ ДАННЫХ» author=»Перфилов Константин Александрович, Иванов Александр Иванович, Проценко Екатерина Дмитриевна» publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2017-03-29″ edition=»ЕВРАЗИЙСКИЙ СОЮЗ УЧЕНЫХ_30.04.2015_04(13)» ebook=»yes» ]