

Введение
Высокотемпературные сверхпроводники — семейство материалов с общей структурной особенностью, относительно хорошо разделёнными медно-кислородными плоскостями. Их также называют сверхпроводниками на основе купратов [4]. Температура сверхпроводящего перехода, которая может быть достигнута в некоторых составах в этом семействе, является самой высокой среди всех известных сверхпроводников (материал, который при определенных условиях приобретает сверхпроводящие свойства).
Чрезвычайно широкий спектр применения ВТСП-материалов обусловлен отсутствием потерь на постоянном токе и небольшими потерями на переменном, экранированием магнитных и электромагнитных полей, возможностью передачи сигналов с минимальными искажениями, а также выполнения аналоговых и цифровых функций при 1000-кратном уменьшении мощности рассеяния и 10-20-кратном повышении быстродействия в сравнении с современными полупроводниковыми приборами.
Исследование по изучению свойств электронной структуры высокотемпературных сверхпроводников в лаборатории теоретической физики и волновых явлений СФУ, потребовало значительных вычислительных ресурсов суперкомпьютерного комплекса СФУ [1].
Описание задачи
Работа направлена на изучение эволюции электронной структуры высокотемпературных сверхпроводников с допированием. Ранее эта задача решалась с учетом статических корреляций в системе, был обнаружен ряд квантовых фазовых переходов, связанных с изменением топологии поверхности Ферми с допированием, и показана их связь со свойствами купратных сверхпроводников.
Учет статических корреляций оправдан в области достаточно низких температур, реалистичное описание систем требует учета динамических эффектов. Решение этой задачи позволит глубже разобраться в природе высокотемпературной сверхпроводимости и позволит перейти к анализу возможных механизмов сверхпроводящего спаривания. Задача представляет собой замкнутую систему самосогласованных уравнений, решаемых на сетке значений двумерного волнового вектора зоны Бриллюэна с дальнейшим суммированием по мацубаровским частотам. Минимально допустимое ограничение для разбиения зоны Бриллюэна составляет 10000 значений, допустимое ограничение на суммирование по частотам составляет порядка 500 значений. Для самосогласования решений необходимо 10-50 итераций.
Таким образом, для персонального компьютера задача, по сути, является трудно решаемой. Первоначально программа реализовывалась с использованием технологии MPI. В итоге для расчёта результирующего массива размером 173376 элементов требовалось приблизительно 20-30 минут (при хорошей сходимости) на 12 узлах кластера, которые используют по два четырехядерных процессора Intel Xeon E5345 в каждом узле. При этом для получения лучших результатов необходимо многократно (при различных входных параметрах) рассчитывать массив в 5-10 раз большего размера и с большей точностью. Это означало, что время выполнения увеличится в разы. Соответственно, задача в экономическом плане получилась довольно затратной. Для увеличения быстродействия и сокращения вычислительных затрат было принято решение переложить алгоритм на гибридную архитектуру и задействовать в вычислениях графические ускорители Nvidia M2090, имеющиеся в арсенале центра высокопроизводительных вычислений СФУ. Такой выбор можно объяснить тем, что с задачами, где необходимо рассчитывать большие объёмы независимых данных, хорошо справляется именно гибридная система с GPU [5].
Математическое описание алгоритма
Имеем следующую систему самосогласованных уравнений [6], подлежащих численному решению.




Данный интеграл считается методом Симпсона.
После численного расчета системы (1)-(3) мы получаем функцию Грина, определенную на комплексных мацубаровских частотах.
Параллельная реализация с использованием CUDA
Анализ профилировщиком MS Visual Studio 2012 программной реализации последовательного вычислительного алгоритма решающего вышеописанные уравнения численными методами позволяет определить участки кода, которые нуждаются в ускорении.
Рассмотрение усеченного дерева вызовов последовательной программы (рисунок 1) с показателями загрузки ЦП дало понимание того, что основными потребителями процессорного времени являются два блока программного кода: расчет функции Грина (имя в коде — fun_find_Green_fun), расчёт Дельта функции (имя в коде — fun_find_delta). Поэтому основной упор по распараллеливанию был сделан именно на них.
Рисунок 1. Дерево вызовов программы
Для компиляции параллельного кода CUDA использовался компилятор nvcc (Nvidia CUDA Compiler) под операционной системой Linux. Для создания параллельного кода применялась среда программирования Nsight Eclipse Edition, именно она позволяет отлаживать код GPU, производить его профилировку, а также увеличивает удобство программирования для графических ускорителей Nvidia.
В процессе преобразования последовательного кода в код CUDA [2,3], создано несколько функций, исполняющихся на устройстве GPU (device), в терминологии CUDA они называются ядрами (kernels) и имеют атрибут __global__. Код внутри ядра выполняется множеством нитей параллельно. Нить GPU имеет координаты во вложенных трехмерных декартовых равномерных сетках (grid). В контексте каждой нити значения координат и размерностей доступны через встроенные переменные. Код ядра начинается с определения индекса исполняемой нити. От него зависит, с какими элементами, обрабатываемых массивов, будет работать текущая нить. В общем случае соответствие нитей и частей задачи может быть любым, например, одна нить может обрабатывать не по одному элементу от используемых массивов, а определенный диапазон. Например, для расчёта массива функции Грина в последовательном варианте программы выполнялось несколько вложенных циклов, но в результате распараллеливания два цикла верхнего уровня перестали быть необходимы по причине того, что задача была распределена между нитями в двумерной сетке, количество которых пропорционально итерациям этих циклов.
Также запускаемые ядром нити используют L1 кэш. Память L1 кэша размещена непосредственно в каждом мультипроцессоре. В данном случае он служит в качестве буфера для данных из глобальной памяти, тем самым повышается эффективность её использования. Об необходимости применения L1 кэша, можно судить, если отключить его совсем, в таком случае программа выполняется на 49% медленнее.
Ядра CUDA программы помимо параллельного выполнения множеством нитей на одном GPU, также параллельно запускались и на втором аналогичном GPU. Поскольку API исполняющей среды CUDA предполагает, что каждый GPU управляется отдельным потоком CPU, то для параллельного запуска ядра на двух GPU создавался второй дополнительный поток на хост устройстве.
Результаты применения программно-аппаратного решения
Для разработанного ПО выполнено ряд тестовых запусков, которые позволили отследить правильность и эффективность распараллеливания.
Правильность работы распараллеленного кода проверялась путём сверки промежуточных и выходных данных параллельной программы с соответствующими данными последовательной программы, они должны быть идентичны.
При проверке эффективности оптимизации и распараллеливания кода, сравнивалось время выполнения программ на 12 узлах кластерной системы СФУ (MPI код) и на двух GPU вычислителях гибридного сервера (CUDA код). Входные данные программ, написанных на MPI и CUDA, одинаковы.
Результаты тестов показаны на рисунке 2. На гибридном сервере программа выполняется в среднем быстрее в 2,05 раза, по сравнению с кластерной системой из 12 узлов. Этого следовало ожидать т.к. заявленная суммарная производительность 12 узлов с процессорами Intel Xeon E5345 (в каждом узле по два процессора) меньше чем у двух Tesla M2090 в 1,83 раза. А дополнительную разницу в скорости выполнения дало то что, помимо вычислений в MPI программе время также тратиться ещё и на передачу сообщений между всеми процессами.
В дополнении к ускорению быстродействия расчётов, использование архитектуры CUDA для решения данной задачи дало возможность уменьшить количество потребляемой электроэнергии, в сравнении с кластерной конфигурацией, почти в 6 раз.
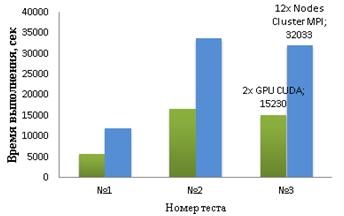

Рисунок 2. Результаты тестовых замеров времени выполнения
Итогом выполнения программы являются, полученные посредством решения систем математических уравнений, функция Грина и Дельта функция, представленные в виде массивов комплексных значений. Их нахождение было необходимо для дальнейшей обработки и использования в анализе изменений характеристик электронного спектра ВТСП купратов.
Список литературы:
- Астриков Д.Ю., Кузьмин Д.А., Панасюк А.И. Создание вычислительных сервисов на базе высокопроизводительных ресурсов СФУ // Пятая международная конференция «Системный анализ и информационные технологии» САИТ — 2013 (19-25 сентября 2013 г., г. Красноярск, Россия): Труды конференции. В 2-х т. — Т. 2. — Красноярск: ИВМ СО РАН, 2013. — с. 317-321.
- Боресков А.В. и др. Параллельные вычисления на GPU. Архитектура и программная модель CUDA // Учеб. пособие/Предисл.: В.А. Садовничий. –М.: Издательство Московского университета, 2012. -336 стр.
- Гергель В.П. Современные языки и технологии параллельного программирования // Учебник/Предисл.: В.А. Садовничий. –М.: Издательство Московского университета, 2012. — 408 стр.
- Садовский М.В. Высокотемпературная сверхпроводимость в слоистых соединениях на основе железа / М.В. Садовский // УФН. – 2008. – T. 178. – C. 1243.
- Шаров В.В., Черников С.В. Анализ эффективности решения задачи N-тел на различных вычислительных архитектурах // Седьмая международная научно-практическая конференция «Молодежь и наука: реальность и будущее»: Материалы конференции / Редкол.: Т.Н. Рябченко, Е.И. Бурьянова: в 2 томах. –Т.1 — Невинномысск: НИЭУП, 2014. – с. 47-50.
- Plakida, N.M. Electron spectrum and superconductivity in the t-J model at moderate doping / Plakida N.M., Oudovenko V.S. // Phys. B. – 1999. – V. 59. – P. 11949.[schema type=»book» name=»ПРИМЕНЕНИЕ ГИБРИДНОЙ ВЫЧИСЛИТЕЛЬНОЙ АРХИТЕКТУРЫ ДЛЯ ИЗУЧЕНИЯ СВОЙСТВ ЭЛЕКТРОННОЙ СТРУКТУРЫ ВЫСОКОТЕМПЕРАТУРНЫХ СВЕРХПРОВОДНИКОВ» description=»В статье представлен вариант параллельной реализации на гибридной вычислительной архитектуре программного комплекса, используемого в лаборатории теоретической физики и волновых явлений СФУ для изучения свойств электронной структуры высокотемпературных сверхпроводников. Программный комплекс реализует задачу, представляющую собой замкнутую систему самосогласованных уравнений, решаемых на сетке значений двумерного волнового вектора зоны Бриллюэна с дальнейшим суммированием по мацубаровским частотам. Параллельная реализация для GPU, выполняющаяся на гибридном сервере с двумя графическими ускорителями Nvidia Tesla, показала отличные результаты, как по скорости расчетов, так и по энергоэффективности. » author=» Шаров Вадим Витальевич, Кузьмин Дмитрий Александрович » publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2017-05-26″ edition=»ЕВРАЗИЙСКИЙ СОЮЗ УЧЕНЫХ_ 30.01.2015_01(10)» ebook=»yes» ]