

Введение.
Методы машинного обучения на основе сжатия описания начальной прецедентной информации стали привлекать внимание исследователей в области теоретической информатики и разработчиков интеллектуализированного программного обеспечения после появления парадигмы MDL – minimum description length [5]. Эта парадигма основана на принципе «бритвы Оккама», согласно которому лучшей гипотезой для объяснения данных является та, которая соответствует наибольшему их сжатию. Под сжатием данных понимается процесс, который приводит к уменьшению объёма данных без потери возможности их использования для получения целевой информации. Теоретической основой и математическим обоснованием построения теории обучения (эмпирической индукции) на основе сжатия явились работы Р. Соломонова и А. Н. Колмогорова [4,6].
Кроме достаточно строго обоснованных теоретических методов, базирующихся на принципах сжатия обучающей информации, известны эвристические подходы к построению алгоритмов машинного обучения на основе «простой структурной закономерности», например, представленные в работе Н. Г. Загоруйко [7], и на поиске кратчайших отделителей – тупиковых тестов и их обобщениях – в работах Ю.И. Журавлёва [1].
Целью этой статьи является дальнейшее изучение теоретических вопросов машинного обучения на основе сжатия начальной прецедентной (обучающей) информации и применения методов теории колмогоровской сложности.
- Декомпрессоры и компрессоры
Определение 1. [3, с. 221] Колмогоровская сложность слова x при заданном способе описания – вычислимой функции (декомпрессоре) D есть ![]()

Здесь и далее l(x) означает длину слова x.
Определение 2. Условная колмогоровская сложность слова x при заданном слове y есть ![]()
![]()

Определение 3. Говорят, что декомпрессор D1 слова x не хуже декомпрессора D2, если ![]()

Теорема 1 (Соломонова–Колмогорова) [3]. Существуют оптимальные декомпрессоры. □
Далее запись KS(x) (или KS(x⌈y)) будет обозначать колмогоровскую сложность (условную сложность) строки по некоторому оптимальному декомпрессору.
Теорема 2 (Колмогоров). Пусть A – перечислимое множество пар (x, a) и ![]()

![]()

Теорема 3. [2, с. 75] Колмогоровская сложность конечной строки x как величина ![]()
![]()
![]()


Определение 4. Пусть x – конечная строка, и множество её компрессоров ![]()

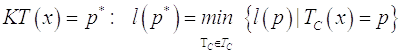

сжатием строки наилучшим компрессором.
Теорема 4 [2, с. 75]. Словарная функция KT (x) сжатия наилучшим компрессором не является вычислимой.
- Сжатие обучающей информации.
Пусть ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()







Пусть P – такая строка, что существует машина Тьюринга T, которая для любого вектора ![]()
![]()
![]()
![]()
![]()
![]()
![]()

Определение 5. Колмогоровская сложность обучающей информации, представленной строкой ![]()
![]()

если существует хотя бы одно слово P, удовлетворяющее указанному условию. В противном случае полагается, что значение сложности не ограничено (+ ∞).
Определение 6. Пусть ![]()
![]()

![]()

сжатием обучающей выборки наилучшим компрессором. □
Подчеркнём, что сжатие ![]()

![]()

Если обучающая выборка не является случайной (в таком случае, согласно теории Колмогорова, она содержит закономерности), то должно выполняться неравенство ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

В общем случае словарная функция ![]()
![]()
- Критерий остановки обучения на основе сжатия.
Принцип MDL гласит: наилучшая гипотеза для данного набора данных та, которая минимизирует сумму длины описания кода гипотезы (также называемой моделью) и длины описания множества данных относительно этой гипотезы. В рассматриваемой постановке слово ![]()
![]()
![]()
Если m – число примеров в обучающей выборке, а величину m(Mn + 1) принять в качестве длины её описания, то сложность одного необъяснённого примера составит Mn + 1. Процесс обучения характеризуется поэтапным усложнением гипотезы, которая классифицирует объекты выборки, по мере необходимости исправлять неправильную классификацию некоторых примеров. Поэтому сложность синтезируемой таким образом гипотезы растет: ![]()
![]()


Критерий остановки процесса обучения определяется значениями суммы ![]()
![]()


Для реализации указанного критерия необходимо научиться оценивать величину удлинения описания гипотезы на шагах коррекции. В некоторых случаях, например, для решающих деревьев, это сделать сравнительно легко. Для параметрических моделей, в частности, для нейронных сетей фиксированной структуры, можно оценивать усложнение гипотезы увеличивающейся величиной максимального модуля параметров, а при растущей структуре сети – оценкой длины описания добавляемых элементов.
Список литературы:
- Дмитриев А.Н., Журавлев Ю.И., Кренделев Ф.П. О математических принципах классификации предметов и явлений // Дискретный анализ. Новосибирск: ИМ СО АН СССР. 1966. Вып. 7. С. 3 – 11.
- Донской В.И. Алгоритмические модели обучения классификации: обоснование, сравнение, выбор. Симферополь: ДИАЙПИ, 2014. 228 с.
- Колмогоров А.Н. Теория информации и теория алгоритмов. М.: Наука, 1987. 304 с.
- Колмогоров А.Н. Три подхода к определению понятия «количество информации» // Проблемы передачи информации. N.1. №1. С. 3–11.
- Rissanen, J. Modeling by shortest data description // Automatica. 1978. 14 (5). P. 465–658.
- Solomonoff J. A Formal Theory of Inductive Inference. Part I // Information and Control. 1964. 7 (1). P. 1–22.
- Zagoruiko N.G., Samochvalov K.F. Hypotheses of the Simplicity in the Pattern Recognition: Proc. of Second Int. Joint Conf. on Artificial Intelligence. London: William Kaufmann, 1971. P. 318-321[schema type=»book» name=»МАШИННОЕ ОБУЧЕНИЕ И СЖАТИЕ ПРЕЦЕДЕНТНОЙ ИНФОРМАЦИИ» description=»Целью этой статьи является изучение теоретических вопросов машинного обучения на основе сжатия начальной прецедентной (обучающей) информации. Для достижения этой цели используются методы теории колмогоровской сложности. Даны определения сложности обучающей информации. Показано, как процесс построения гипотезы, основанной на сжатии обучающей информации, обеспечивает возможность эмпирического обобщения и достижения обучаемости. Предложен критерий остановки процесса машинного обучения на основе сжатия. Для реализации указанного критерия необходимо научиться оценивать величину удлинения описания гипотезы на шагах коррекции. В некоторых случаях, например, для решающих деревьев, это сделать сравнительно легко. Для параметрических моделей, в частности, для нейронных сетей фиксированной структуры, можно оценивать усложнение гипотезы увеличивающейся по мере обучения величиной максимального модуля параметров, а при растущей структуре сети – оценкой длины описания добавляемых элементов.» author=»Донской Владимир Иосифович» publisher=»БАСАРАНОВИЧ ЕКАТЕРИНА» pubdate=»2016-12-26″ edition=»euroasia-science.ru_26-27.02.2016_2(23)» ebook=»yes» ]